主题
衡石系统函数列表
衡石系统提供了丰富的函数,用于查询数据。
聚合函数
FIRST
获取指定列中第一个记录的值。
函数语法
text
FIRST(expression)参数说明
expression
必填,任意类型或者返回值是任意类型的表达式, 不允许使用聚合函数和子查询。
返回值类型
任意类型
示例1
获取学生姓名中的第一条记录。
FIRST({student_name})LAST
获取指定列中最后一个记录的值。
函数语法
text
LAST(expression)参数说明
expression
必填,任意类型或者返回值是任意类型的表达式, 不允许使用聚合函数和子查询。
返回值类型
任意类型
示例1
获取学生分数中的最后一条记录。
LAST({student_score})MEDIAN
获取指定数值列的中位数。
函数语法
text
MEDIAN(expression)参数说明
expression
必填,数字类型参数或者返回值是数字类型的表达式, 不允许使用聚合函数和子查询。 可选类型:NUMBER
返回值类型
NUMBER
示例1
计算所有学生的成绩的中位数。
MEDIAN({student_score})PERCENTILE
计算百分位数,返回一个对应于排序中指定分数的值,如有必要就在相邻的输入项之间插值。
函数语法
text
PERCENTILE(expr1,literal_percent)参数说明
expr1
必填,要计算百分位数的表达式,数字类型参数或者返回值是数字类型的表达式, 不允许使用聚合函数和子查询。 可选类型:NUMBER
literal_percent
必填,需要的百分位数,数字类型参数或者返回值是数字类型的表达式, 不允许使用聚合函数和子查询。 可选类型:NUMBER
返回值类型
NUMBER
示例1
计算学生成绩中位数。
PERCENTILE({student_score},0.5)PERCENTILE_CONT
计算连续百分位数,返回一个对应于排序中指定分数的值,如有必要就在相邻的输入项之间插值。
函数语法
text
PERCENTILE_CONT(literal_percent) WITHIN GROUP (ORDER BY expr1 [ DESC | ASC ] )参数说明
literal_percent
必填,需要的百分位数,数字类型参数或者返回值是数字类型的表达式, 不允许使用聚合函数和子查询。 可选类型:NUMBER
expr1
必填,数字类型,不可使用聚合函数或者子查询。可选类型:NUMBER
返回值类型
NUMBER
示例1
计算学生成绩中位数。
PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY {student_score} DESC )MODE
返回出现频次最高的一个值,频次相同则返回第一个。
函数语法
text
MODE() WITHIN GROUP ( ORDER BY expr1 [ DESC ] )参数说明
expr1
必填,任意类型,可以是用于计算的列,不可使用聚合函数或者子查询。
返回值类型
NUMBER
示例1
找到所有学生名字中重复次数最多的名字。
MODE() WITHIN GROUP (ORDER BY {student_name})NTH
获取第i个数值。
函数语法
text
NTH(expr1,expr2)参数说明
expr1
必填,任意类型或者返回值是任意类型的表达式, 不允许使用聚合函数和子查询。
expr2
必填,数值类型或者返回值是数值类型的表达式, 不允许使用聚合函数和子查询。
返回值类型
任意类型
示例1
获取所有学生成绩中的第二条记录。
NTH({student_score},2)LIST_COLLECT
聚合函数,把 arg 的参数收集为数组。
函数语法
text
LIST_COLLECT(expression)参数说明
expression
必填,任意类型参数, 不允许使用聚合函数和子查询。
返回值类型
ARRAY
示例1
将所有学生的名字拼接成一个数组。
LIST_COLLECT({student_name})LIST_COLLECT_FLATTEN
聚合函数, 把数组参数中的元素收集打平为数组。
函数语法
text
LIST_COLLECT_FLATTEN(expression)参数说明
expression
必填,数组类型参数, 不允许使用聚合函数和子查询。 可选类型:ARRAY
返回值类型
ARRAY
示例1
将每个班级中的每个学生名字数组转化为一个数组
LIST_COLLECT_FLATTEN({student_names})SET_COLLECT
聚合函数, 把 arg 的参数收集为去重数组。
函数语法
text
SET_COLLECT(expression)参数说明
expression
必填,任意类型参数, 不允许使用聚合函数和子查询。
返回值类型
ARRAY
示例1
将所有学生的名字去重后拼接成一个数组。
SET_COLLECT({student_name})SET_COLLECT_FLATTEN
聚合函数,把 arr 的参数收集打平为去重数组。
函数语法
text
SET_COLLECT_FLATTEN(expression)参数说明
expression
必填,任意类型参数, 必填,数组类型参数, 不允许使用聚合函数和子查询。 可选类型:ARRAY 。
返回值类型
ARRAY
示例1
将每个班级中的每个学生名字数组中的名字收集去重后转化为一个数组
SET_COLLECT_FLATTEN({student_names})MIN_BY
获取 compare 列最小那行对应的 arg 列的值, 如有多个最小值取随机一个。
函数语法
text
MIN_BY(expr1,expr2)参数说明
expr1
必填,任意类型参数,用于获取最小值数据的列, 不允许使用聚合函数和子查询。
expr2
必填,任意类型参数,用于进行比较地列, 不允许使用聚合函数和子查询。
返回值类型
任意类型
示例1
获取所有学生中分数最低的学生的姓名。
MIN_BY({student_name},{student_score})MAX_BY
获取 compare 列最大那行对应的 arg 列的值,如有多个最大值取随机一个。
函数语法
text
MAX_BY(expr1,expr2)参数说明
expr1
必填,任意类型参数,用于获取最大值数据的列, 不允许使用聚合函数和子查询。
expr2
必填,任意类型参数,用于进行比较地列, 不允许使用聚合函数和子查询。
返回值类型
任意类型
示例1
获取所有学生中分数最高的学生的姓名。
MAX_BY({student_name},{student_score})SUM
此函数返回各组的总和。 将忽略 null 值。
函数语法
text
SUM(expression)参数说明
expression
必填,数字类型参数或者返回值是数字类型的表达式, 不允许使用聚合函数和子查询。 可选类型:NUMBER
返回值类型
NUMBER
示例1
计算所有学生的成绩总和。
SUM({student_score})AVG
获取指定数值列的平均值。
函数语法
text
AVG(expression)参数说明
expression
必填,数字类型参数或者返回值是数字类型的表达式, 不允许使用聚合函数和子查询。 可选类型:NUMBER
返回值类型
NUMBER
示例1
计算所有学生的平均成绩。
AVG({student_score})MAX
获取指定列的最大值。
函数语法
text
MAX(expression)参数说明
expression
必填,参数可以是任意类型,不允许使用聚合函数和子查询。
返回值类型
任意类型
示例1
获取学生成绩中最高的分数。
MAX({student_score})MIN
获取指定列的最小值。
函数语法
text
MIN(expression)参数说明
expression
必填,参数可以是任意类型, 不允许使用聚合函数和子查询。
返回值类型
任意类型
示例1
获取所有学生成绩中最低的分数。
MIN({student_score})COUNT
获取指定列的值的数目。
函数语法
text
COUNT(expression)参数说明
expression
必填,任意类型, 不允许使用聚合函数和子查询。
返回值类型
NUMBER
示例1
获取学生总数。
COUNT({student_id})DISTINCT_COUNT
获取指定列中非重复结果的数目。
函数语法
text
DISTINCT_COUNT(expression)参数说明
expression
必填,任意类型,不允许使用聚合函数和子查询。
返回值类型
NUMBER
示例1
获取全校学生的名字中共有多少个不同的名字。
DISTINCT_COUNT({student_name})CORR
返回两个数字列的相关系数。
函数语法
text
CORR(arg1, arg2)参数说明
arg1
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
arg2
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
返回值类型
NUMBER
示例1
获取广告投入费与销售额的相关性。
CORR({advertisement_expense},{sales_valume})COVAR_POP
返回两个数字列的总体协方差。
函数语法
text
COVAR_POP(arg1, arg2)参数说明
arg1
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
arg2
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
返回值类型
NUMBER
COVAR_SAMP
返回两个数字列的样本协方差。
函数语法
text
COVAR_SAMP(arg1, arg2)参数说明
arg1
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
arg2
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
返回值类型
NUMBER
REGR_AVGX
返回自变量的平均值 (sum(arg2)/N)。
函数语法
text
REGR_AVGX(arg1, arg2)参数说明
arg1
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
arg2
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
返回值类型
NUMBER
REGR_AVGY
返回因变量的平均值 (sum(arg1)/N)。
函数语法
text
REGR_AVGY(arg1, arg2)参数说明
arg1
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
arg2
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
返回值类型
NUMBER
REGR_COUNT
统计两个表达式都不为空的输入行的数目。
函数语法
text
REGR_COUNT(arg1, arg2)参数说明
arg1
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
arg2
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
返回值类型
NUMBER
REGR_INTERCEPT
返回由(arg2, arg1)对决定的最小二乘拟合的线性方程的 arg1 截距。
函数语法
text
REGR_INTERCEPT(arg1, arg2)参数说明
arg1
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
arg2
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
返回值类型
NUMBER
REGR_R2
相关系数的平方。
函数语法
text
REGR_R2(arg1, arg2)参数说明
arg1
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
arg2
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
返回值类型
NUMBER
REGR_SLOPE
由(arg2, arg1)对决定的最小二乘拟合的线性方程的斜率。
函数语法
text
REGR_SLOPE(arg1, arg2)参数说明
arg1
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
arg2
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
返回值类型
NUMBER
REGR_SXX
sum(arg2^2) - sum(arg2)^2/N (自变量的"平方和")。
函数语法
text
REGR_SXX(arg1, arg2)参数说明
arg1
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
arg2
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
返回值类型
NUMBER
REGR_SXY
sum(arg2*arg1) - sum(arg2) * sum(arg1)/N (自变量乘以因变量的"积之合")。
函数语法
text
REGR_SXY(arg1, arg2)参数说明
arg1
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
arg2
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
返回值类型
NUMBER
REGR_SYY
sum(arg1^2) - sum(arg1)^2/N (因变量的"平方和")。
函数语法
text
REGR_SYY(arg1, arg2)参数说明
arg1
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
arg2
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
返回值类型
NUMBER
STDDEV_SAMP
返回数字列的样本标准偏差。
函数语法
text
STDDEV_SAMP(arg1)参数说明
arg1
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
返回值类型
NUMBER
STDDEV_POP
返回数字列的总体标准偏差。
函数语法
text
STDDEV_POP(arg1)参数说明
arg1
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
返回值类型
NUMBER
VAR_POP
返回数字列的总体方差(总体标准偏差的平方)。
函数语法
text
VAR_POP(arg1)参数说明
arg1
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
返回值类型
NUMBER
VAR_SAMP
返回数字列的样本方差(样本标准偏差的平方)。
函数语法
text
VAR_SAMP(arg1)参数说明
arg1
必填,不允许使用聚合函数和子查询。可选类型:NUMBER
返回值类型
NUMBER
STRING_AGG
把指定表达式拼接成新字符串, 用 delimiter 分割。
函数语法
text
STRING_AGG(arg1, arg2) [WITHIN GROUP (ORDER BY arg3 ASC, ...)]参数说明
arg1
必填,要进行拼接的字符串,不允许使用聚合函数和子查询。可选类型:STRING
arg2
必填,拼接字符串所用的分割符。可选类型:STRING
[WITHIN GROUP (ORDER BY arg3 ASC, ...)]
选填,分组子句,按照指定的表达式arg3来进行分组并拼接字符串。
返回值类型
STRING
示例1
获取每个月发布的电影,并将电影名使用","拼接起来。
STRING_AGG({zh_name},',') WITHIN GROUP (ORDER BY {month} ASC)部分返回结果如下:
json
{
"data": {
"data": [
[
"风之谷,7号房的礼物,阿凡达,爱在黎明破晓前,哈利·波特与魔法石,小鞋子,中央车站,蝴蝶效应,电锯惊魂,幸福终点站,大闹天宫,城市之光,当幸福来敲门,我们俩,非常嫌疑犯,假如爱有天意,喜宴,未麻的部屋,霸王别姬,超能陆战队,小森林,布达佩斯大饭店,爱在日落黄昏时,喜剧之王,射雕英雄传之东成西就,我爱你,甜蜜蜜,纵横四海,大卫·戈尔的一生,国王的演讲,巴黎淘气帮,美国往事,摩登时代,禁闭岛,猜火车,沉默的羔羊,黑客帝国,暖暖内含光,音乐之声,指环王3:王者无敌,情书,教父,导盲犬小Q,秒速5厘米,贫民窟的百万富翁,浪潮,冰川时代,窃听风暴,致命ID,超脱,指环王2:双塔奇兵,龙猫,倩女幽魂,爱·回家,十二怒汉,海盗电台,七武士,岁月神偷,杀人回忆,玛丽和马克思,疯狂原始人,天使爱美丽,指环王1:魔戒再现,泰坦尼克号,萤火虫之墓,雨中曲,罪恶之城,上帝之城,末路狂花,穆赫兰道,被解救的姜戈,驯龙高手,哪吒闹海,阳光姐妹淘,碧海蓝天,狩猎,被嫌弃的松子的一生,活着,鬼子来了,魂断蓝桥,勇敢的心,菊次郎的夏天,低俗小说,花样年华,速度与激情5,一一,春光乍泄,钢琴家,角斗士,变脸,阿甘正传,初恋这件小事,再次出发之纽约遇见你,楚门的世界,忠犬八公的故事,E.T.,恋恋笔记本,勇闯夺命岛,神偷奶爸,人工智能,惊魂记,疯狂的石头,机器人总动员,死亡诗社,告白,廊桥遗梦,玩具总动员3,千与千寻,拯救大兵瑞恩,海豚湾,侧耳倾听,穿越时空的少女,唐伯虎点秋香,魔女宅急便,月球,借东西的小人阿莉埃蒂,终结者2:审判日,蝙蝠侠:黑暗骑士,牯岭街少年杀人事件,重庆森林,曾经,狮子王,恐怖直播,幽灵公主,罗生门,海洋,忠犬八公物语,小森林,英雄本色,哈利·波特与死亡圣器,怦然心动,飞屋环游记,阳光灿烂的日子,蝙蝠侠:黑暗骑士崛起,两杆大烟枪,源代码,第六感,新龙门客栈,天空之城,荒蛮故事,无耻混蛋,饮食男女,记忆碎片,卢旺达饭店,追随,香水,荒野生存,肖申克的救赎,傲慢与偏见,上帝也疯狂,七宗罪,两小无猜,战争之王,撞车,时空恋旅人,燕尾蝶,达拉斯买家俱乐部,萤火之森,无间道,美国丽人,偷拐抢骗,勇士,红辣椒,消失的爱人,罗马假日,搏击俱乐部,盗梦空间,这个杀手不太冷,哈尔的移动城堡,穿条纹睡衣的男孩,断背山,东邪西毒,入殓师,蓝色大门,熔炉,海上钢琴师,可可西里,致命魔术,末代皇帝,大话西游之大圣娶亲,素媛,千钧一发,恐怖游轮,爆裂鼓手,西西里的美丽传说,心迷宫,放牛班的春天,梦之安魂曲,大话西游之月光宝盒,星际穿越,辛德勒的名单,这个男人来自地球,天堂电影院,触不可及,寿司之神,夜访吸血鬼,谍影重重,一次别离,少年派的奇幻漂流,东京物语,枪火,与狼共舞,无敌破坏王,加勒比海盗,真爱至上,卡萨布兰卡,青蛇,谍影重重3,谍影重重2,黑客帝国3:矩阵革命,爱在暹罗,怪兽电力公司,完美的世界,飞越疯人院,让子弹飞,美丽人生,乱世佳人,虎口脱险,血钻,猫鼠游戏,迁徙的鸟,闻香识女人,控方证人,发条橙,不一样的天空,教父3,荒岛余生,雨人,绿里奇迹,辩护人,阿飞正传,教父2,遗愿清单,V字仇杀队,三傻大闹宝莱坞,大鱼,剪刀手爱德华,燃情岁月,蝴蝶,本杰明·巴顿奇事,黄金三镖客,心灵捕手,朗读者,黑天鹅,麦兜故事,地球上的星星,叫我第一名,美丽心灵,英国病人,我是山姆"
]
]
}
}JSON_AGG
把指定表达式拼接成新JSON数组。
函数语法
text
JSON_AGG(arg1) [WITHIN GROUP (ORDER BY arg2 ASC, ...)]参数说明
arg1
必填,要进行拼接的字符串,不允许使用聚合函数和子查询。可选类型:STRING
[WITHIN GROUP (ORDER BY arg2 ASC, ...)]
选填,分组子句,按照指定的表达式arg2来进行分组并拼接JSON字符串。
返回值类型
JSON
示例1
获取每个月发布的电影名,并将电影名拼接成一个JSON字符串。
JSON_AGG({zh_name}) WITHIN GROUP (ORDER BY {month} ASC)部分返回结果如下
json
{
"data": {
"data": [
[
"[\"风之谷\", \"7号房的礼物\", \"阿凡达\", \"爱在黎明破晓前\", \"哈利·波特与魔法石\", \"小鞋子\", \"中央车站\", \"蝴蝶效应\", \"电锯惊魂\", \"幸福终点站\", \"大闹天宫\", \"城市之光\", \"当幸福来敲门\", \"我们俩\", \"非常嫌疑犯\", \"假如爱有天意\", \"喜宴\", \"未麻的部屋\", \"霸王别姬\", \"超能陆战队\", \"小森林\", \"布达佩斯大饭店\", \"爱在日落黄昏时\", \"喜剧之王\", \"射雕英雄传之东成西就\", \"我爱你\", \"甜蜜蜜\", \"纵横四海\", \"大卫·戈尔的一生\", \"国王的演讲\", \"巴黎淘气帮\", \"美国往事\", \"摩登时代\", \"禁闭岛\", \"猜火车\", \"沉默的羔羊\", \"黑客帝国\", \"暖暖内含光\", \"音乐之声\", \"指环王3:王者无敌\", \"情书\", \"教父\", \"导盲犬小Q\", \"秒速5厘米\", \"贫民窟的百万富翁\", \"浪潮\", \"冰川时代\", \"窃听风暴\", \"致命ID\", \"超脱\", \"指环王2:双塔奇兵\", \"龙猫\", \"倩女幽魂\", \"爱·回家\", \"十二怒汉\", \"海盗电台\", \"七武士\", \"岁月神偷\", \"杀人回忆\", \"玛丽和马克思\", \"疯狂原始人\", \"天使爱美丽\", \"指环王1:魔戒再现\", \"泰坦尼克号\", \"萤火虫之墓\", \"雨中曲\", \"罪恶之城\", \"上帝之城\", \"末路狂花\", \"穆赫兰道\", \"被解救的姜戈\", \"驯龙高手\", \"哪吒闹海\", \"阳光姐妹淘\", \"碧海蓝天\", \"狩猎\", \"被嫌弃的松子的一生\", \"活着\", \"鬼子来了\", \"魂断蓝桥\", \"勇敢的心\", \"菊次郎的夏天\", \"低俗小说\", \"花样年华\", \"速度与激情5\", \"一一\", \"春光乍泄\", \"钢琴家\", \"角斗士\", \"变脸\", \"阿甘正传\", \"初恋这件小事\", \"再次出发之纽约遇见你\", \"楚门的世界\", \"忠犬八公的故事\", \"E.T.\", \"恋恋笔记本\", \"勇闯夺命岛\", \"神偷奶爸\", \"人工智能\", \"惊魂记\", \"疯狂的石头\", \"机器人总动员\", \"死亡诗社\", \"告白\", \"廊桥遗梦\", \"玩具总动员3\", \"千与千寻\", \"拯救大兵瑞恩\", \"海豚湾\", \"侧耳倾听\", \"穿越时空的少女\", \"唐伯虎点秋香\", \"魔女宅急便\", \"月球\", \"借东西的小人阿莉埃蒂\", \"终结者2:审判日\", \"蝙蝠侠:黑暗骑士\", \"牯岭街少年杀人事件\", \"重庆森林\", \"曾经\", \"狮子王\", \"恐怖直播\", \"幽灵公主\", \"罗生门\", \"海洋\", \"忠犬八公物语\", \"小森林\", \"英雄本色\", \"哈利·波特与死亡圣器\", \"怦然心动\", \"飞屋环游记\", \"阳光灿烂的日子\", \"蝙蝠侠:黑暗骑士崛起\", \"两杆大烟枪\", \"源代码\", \"第六感\", \"新龙门客栈\", \"天空之城\", \"荒蛮故事\", \"无耻混蛋\", \"饮食男女\", \"记忆碎片\", \"卢旺达饭店\", \"追随\", \"香水\", \"荒野生存\", \"肖申克的救赎\", \"傲慢与偏见\", \"上帝也疯狂\", \"七宗罪\", \"两小无猜\", \"战争之王\", \"撞车\", \"时空恋旅人\", \"燕尾蝶\", \"达拉斯买家俱乐部\", \"萤火之森\", \"无间道\", \"美国丽人\", \"偷拐抢骗\", \"勇士\", \"红辣椒\", \"消失的爱人\", \"罗马假日\", \"搏击俱乐部\", \"盗梦空间\", \"这个杀手不太冷\", \"哈尔的移动城堡\", \"穿条纹睡衣的男孩\", \"断背山\", \"东邪西毒\", \"入殓师\", \"蓝色大门\", \"熔炉\", \"海上钢琴师\", \"可可西里\", \"致命魔术\", \"末代皇帝\", \"大话西游之大圣娶亲\", \"素媛\", \"千钧一发\", \"恐怖游轮\", \"爆裂鼓手\", \"西西里的美丽传说\", \"心迷宫\", \"放牛班的春天\", \"梦之安魂曲\", \"大话西游之月光宝盒\", \"星际穿越\", \"辛德勒的名单\", \"这个男人来自地球\", \"天堂电影院\", \"触不可及\", \"寿司之神\", \"夜访吸血鬼\", \"谍影重重\", \"一次别离\", \"少年派的奇幻漂流\", \"东京物语\", \"枪火\", \"与狼共舞\", \"无敌破坏王\", \"加勒比海盗\", \"真爱至上\", \"卡萨布兰卡\", \"青蛇\", \"谍影重重3\", \"谍影重重2\", \"黑客帝国3:矩阵革命\", \"爱在暹罗\", \"怪兽电力公司\", \"完美的世界\", \"飞越疯人院\", \"让子弹飞\", \"美丽人生\", \"乱世佳人\", \"虎口脱险\", \"血钻\", \"猫鼠游戏\", \"迁徙的鸟\", \"闻香识女人\", \"控方证人\", \"发条橙\", \"不一样的天空\", \"教父3\", \"荒岛余生\", \"雨人\", \"绿里奇迹\", \"辩护人\", \"阿飞正传\", \"教父2\", \"遗愿清单\", \"V字仇杀队\", \"三傻大闹宝莱坞\", \"大鱼\", \"剪刀手爱德华\", \"燃情岁月\", \"蝴蝶\", \"本杰明·巴顿奇事\", \"黄金三镖客\", \"心灵捕手\", \"朗读者\", \"黑天鹅\", \"麦兜故事\", \"地球上的星星\", \"叫我第一名\", \"美丽心灵\", \"英国病人\", \"我是山姆\"]"
]
]
}
}窗口函数
注意使用窗口函数时必须同时使用窗口函数所需要的语法:OVER子句
语法
text
function_name([expression [, expression ... ]]) OVER( [ PARTITION BY expr1 ] [ ORDER BY expr2 [ DESC ] ] )子句说明 OVER( [ PARTITION BY expr1 ] [ ORDER BY expr2 [ DESC ] ] )
[ PARTITION BY expr1 ]
可选参数,partition by 会将查询的数据进行分组,窗口函数会独立的处理每一个分组。
[ ORDER BY expr2 [ DESC ] ]
可选参数,根据expr2进行排序。(部分函数,该部分为必选时会在文档中说明)
[ DESC ]
可选参数,默认会使用正序排序,使用DESC参数后结果将会使用倒序排序。
数据示例
下面是示例所用的部分数据: 
ROW_NUMBER
返回当前窗口的行数,计数从 1 开始。
函数语法
text
row_number() OVER( [ PARTITION BY expr1 ] [ ORDER BY expr2 [ DESC ] ] )返回值类型
INTEGER
示例1
获取一月份每部电影在该月中按照电影时长排序的行号
- 使用下面高级表达式新增字段:
text
ROW_NUMBER() OVER (PARTITION BY {month} ORDER BY {runtime} ASC)- 新建图表,维度选择{zh_name},维度排序选择图内排序->升序->图内度量选择新增的指标,拖入上面创建的字段作为度量。
- 使用month字段创建过滤器,过滤类型选择比较,值为1。
- 下面是计算结果:
json
{
"data": {
"data": [
[
"未麻的部屋 ",
1
],
[
"城市之光",
2
],
[
"我们俩 ",
3
],
[
"小鞋子 ",
4
]
]
}
}RANK
窗口函数, 返回当前窗口的排名(保持间隔),计数从 1 开始。
函数语法
text
rank() OVER( [ PARTITION BY expr1 ] ORDER BY expr2 [ DESC ] )必须存在ORDER BY expr2 [ DESC ]表达式
返回值类型
INTEGER
示例1
获取每部电影在各自的上映月份按照评分的排名
- 使用下面高级表达式新增字段:
text
RANK() OVER (PARTITION BY {month} ORDER BY {rate_num} DESC)- 新建图表,维度选择{zh_name},维度排序选择图内排序->升序->图内度量选择新增的指标,拖入上面创建的字段作为度量。
- 下面是部分计算结果:
json
{
"data": {
"data": [
[
"7号房的礼物",
16
],
[
"E.T.",
7
],
[
"V字仇杀队",
12
],
[
"一一",
5
]
]
}
}DENSE_RANK
窗口函数, 返回当前窗口的排名(不保持间隔), 计数从 1 开始。dense_rank与rank的区别在于dense_rank在出现重复排名时,下一个排名会仅接其上的序号,而rank则会跳过因为重复而没有出现的序号。 比如有以下排名: *. dense_rank
| 序号 | id | 分数 |
|---|---|---|
| 1 | 1 | 90 |
| 1 | 2 | 90 |
| 2 | 3 | 85 |
*. rank
| 序号 | id | 分数 |
|---|---|---|
| 1 | 1 | 90 |
| 1 | 2 | 90 |
| 3 | 3 | 85 |
函数语法
text
dense_rank() OVER( [ PARTITION BY expr1 ] ORDER BY expr2 [ DESC ] )必须存在ORDER BY expr2 [ DESC ]表达式
返回值类型
INTEGER
注:具体使用参考RANK
LAG
窗口函数, 向前获得相对于当前记录指定i距离的那条记录的 arg 数据。
函数语法
text
LAG(ARG, I) OVER( [ PARTITION BY expr1 ] [ ORDER BY expr2 [ DESC ] ] )参数说明
ARG
窗口框架
I
指定记录与当前记录的距离。
返回值类型
任意类型
示例1
根据电影评分排序,并获得每一部与在其前一位电影的评分差距。
- 使用下面高级表达式新增字段:
text
{rate_num}-LAG({rate_num},1) OVER (ORDER BY {rate_num})- 新建图表,维度选择{zh_name},维度排序选择字段->升序->数据集->字段rate_num->聚合方式求和,拖入上面创建的字段作为度量。
- 下面是部分计算结果:
json
{
"data": {
"data": [
[
"魂断蓝桥",
null
],
[
"蝙蝠侠:黑暗骑士崛起",
0.014593331143260000
],
[
"城市之光",
0.011929618194699800
],
[
"鬼子来了",
0.039572115056216000
],
[
"机器人总动员",
0.026077190414071000
],
[
"蓝色大门",
0.028898352757097000
],
[
"哪吒闹海",
0.017922166734933000
],
[
"三傻大闹宝莱坞",
0.030600312165916000
],
[
"拯救大兵瑞恩",
0.015233601443470000
],
[
"闻香识女人",
0.098394742235541000
],
[
"大闹天宫",
0.063349320553243000
],
[
"告白",
0.005003553815186000
],
[
"真爱至上",
0.037729605101049000
],
[
"疯狂的石头",
0.060827187262476000
],
[
"七武士",
0.004322621971369000
],
[
"阳光灿烂的日子",
0.055139157921075000
],
[
"青蛇",
0.052122632041574000
],
[
"朗读者",
0.011737644672394000
],
[
"穿条纹睡衣的男孩",
0.029632123187184000
],
[
"纵横四海",
0.045848819427192000
]
],
"schema": [
{
"fieldName": "u_6e32dd593df01482_2",
"config": {},
"nativeType": "text",
"suggestedTypes": [
null
],
"visible": true
},
{
"fieldName": "u_1f0d69977f159963_2",
"config": {},
"nativeType": "numeric",
"suggestedTypes": [
null
],
"visible": true
}
]
}
}NTH_VALUE
获取窗口中第 i 个 arg 值
函数语法
text
NTH_VALUE(ARG, I) OVER( [ PARTITION BY expr1 ] [ ORDER BY expr2 [ DESC ] ] )参数说明
ARG
窗口框架
I
想要获取的数据的行数
返回值类型
任意类型
示例1
获取每个月中排名评分排名第二高的电影
- 使用下面高级表达式新增字段:
text
NTH_VALUE({zh_name}, 2) OVER( PARTITION BY {month} ORDER BY {rate_num} DESC )- 新建表格,维度选择{month}与新建的字段,拖入新建字段建立过滤器,排除null
- 下面是部分计算结果:
json
{
"data": {
"data": [
[
1,
"未麻的部屋"
],
[
2,
"沉默的羔羊"
],
[
3,
"冰川时代"
]
]
}
}LEAD
窗口函数, 向后获得相对于当前记录指定i距离的那条记录的 arg 数据
函数语法
text
LEAD(ARG, I) OVER( [ PARTITION BY expr1 ] [ ORDER BY expr2 [ DESC ] ] )参数说明
ARG
窗口框架
I
指定记录与当前记录的距离。
返回值类型
任意类型
注:具体使用参考LAG
ROLLUP_VALUE
它可以基于部分维度计算度量,一般用于新建指标。
函数语法
text
ROLLUP_VALUE(ARG) OVER( [ PARTITION BY expr1 ] ] )参数说明
ARG
聚合计算表达式
返回值类型
任意类型
示例1
计算所有 votes 的总和,它可用于任意图表中
text
rollup_value(sum({votes})) OVER ()示例2
按照 month 分组后, 计算组内 votes 的总和,它能够用于维度中有 month 的图表中
text
rollup_value(sum({votes})) OVER (partition by {month})LOOKUPVALUE
从其它非关联的数据中计算出结果,展示在当前图表中,只能用于新建指标
函数语法
text
LOOKUPVALUE(ARG1, ARG2, ARG3)参数说明
ARG1
在非关联数据上要计算的聚合表达式,非关联数据集字段信息必须带上数据集 id
ARG2
非关联数据上与本图表可以关联的表达式,非关联数据集字段信息必须带上数据集 id
ARG3
本图表中用于关联的表达式,它必须和图表中的一个维度相同
返回值类型
任意类型
示例1
比如图表用了数据集"销售订单",维度是 year({date}),需要同时展示出数据集"进货明细"表中每年的金额总和。指标表达式如下。请注意表达中使用的是数据集"进货明细"的 id
text
LOOKUPVALUE(SUM({{2}}.{金额}), year({{2}}.{date}), year({date}))其他窗口函数
部分聚合函数也能够作为窗口函数使用。
仅当聚集函数调用后面跟着一个OVER子句时,聚合函数才会像窗口函数那样工作 ,否则它们会按非窗口聚集的方式运行并且为整个集合返回一个单一行。
可以作为窗口函数使用的聚合函数列表如下:
| 函数名 | / | / | / |
|---|---|---|---|
| SUM | AVG | MAX | MIN |
| CORR | COVAR_POP | COVAR_SAMP | REGR_AVGX |
| REGR_AVGY | REGR_COUNT | REGR_INTERCEPT | REGR_R2 |
| REGR_SLOPE | REGR_SXX | REGR_SXY | REGR_SYY |
| STDDEV_POP | STDDEV_SAMP | VAR_POP | VAR_SAMP |
| STRING_AGG | JSON_AGG | COUNT |
[ ORDER BY expr [ DESC | ASC ] ]表达式注意项
这里有一个与窗口函数相关的重要概念:对于每一行,在它的分区中的行集合被称为它的窗口帧。 一些窗口函数只作用在窗口帧中的行上,而不是整个分区。此类函数如果同时使用
ORDER BY,则帧包括从分区开始到当前行的所有行,以及后续任何与当前行在ORDER BY子句上相等的行。
所有的聚合函数在使用OVER子句中的
ORDER BY表达式时,最终的返回结果均会与不使用ORDER BY表达式会有各种各样的差异。
示例1
获取每个班学生的总人数。
COUNT(1) OVER (PARTITION BY {class})示例2
将各个班级的学生姓名按照成绩顺序拼接成一个JSON数组。
JSON_AGG({student_name}) OVER (PARTITION BY {class} ORDER BY {student_score})窗口函数注意事项
使用窗口函数做为图表指标时的注意事项:
- 窗口函数不是聚合函数,不能作为聚合函数所用。
- 图表中有维度列的时候,如果窗口函数使用了 OVER 子句[PARTITION BY expr1]/[ORDER BY expr2],非聚合运算的 expr1 或者 expr2 都必须是图表的维度列
- 假设图表有维度 a,b, 度量为 MAX(COUNT({书籍编号})) OVER (***)。计算的逻辑是:
- 以 a, b 分组,计算 COUNT({书籍编号}) 的值, 得到一个中间结果: (a, b, count_tmp)
- 度量是 MAX(COUNT({书籍编号})) OVER (), 计算结果是:在 count_tmp 列中找出最大值
- 度量是 MAX(COUNT({书籍编号})) OVER (PARTITION BY a), 计算结果是:从(a, tmp) 这个数组中,以a的值为划分依据,找出每个组内tmp的最大值
- 度量是 MAX(COUNT({书籍编号})) OVER (PARTITION BY b), 计算结果是:从(b, tmp) 这个数组中,以b的值为划分依据,找出每个组内tmp的最大值
示例1:
有以下格式的数据:
| zh_name | month | rate_num | prime_genre |
|---|---|---|---|
| 电影1 | 1 | 9.00000 | 剧情 |
接下来要创建统计每个月分别有多少部电影的图表。
新建指标
COUNT(1)命名为 nameCounts。将month与prime_genre字段拖入维度,将nameCounts指标拖入度量。可以得到以下图表:
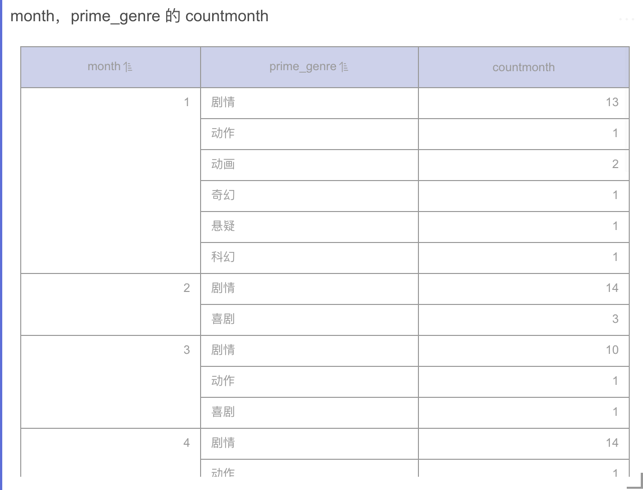
可以看到数据根据维度进行了分组,也就是根据month与prime_genre进行了分组。也就是执行了
GROUP BY {month},{prime_genre}表达式。当我们修改指标相关创建语句为
COUNT(1) OVER ( PARTITION BY {month} )时,图表更新:
图表的意义变为了统计每个月有几种类型的电影。也就是先按照month与prime_genre维度进行了分组计算出了结果后,再按照month进行了分区,最后再进行
COUNT(1)计算。(从(month,nameCounts) 数组中以month为一句进行计算),如果将指标创建语句改为COUNT(1) OVER ( PARTITION BY {prime_genre} )则数组是(prime_genre,nameCounts))当将指标的创建语句改为
COUNT(1) OVER ( PARTITION BY {zh_name} )时,由于zh_name字段并没有出现在维度中,也就是没有出现在GROUP BY表达式中 所以提示出现相关错误。
高级计算函数
衡石系统提供了一些高级计算函数,用于同环比计算、累计计算、移动计算、留存计算、活跃计算等。 此类函数说明的示例都是基于数据库中的 advancedcal 表。 下面是 advancedcal 的数据。
| logindate | username | usertype | energy |
|---|---|---|---|
| 2019-01-05 00:00:00 | A1 | U1 | 10 |
| 2019-01-05 00:00:00 | A2 | U2 | 20 |
| 2019-01-05 00:00:00 | A3 | U1 | 30 |
| 2019-01-05 00:00:00 | A4 | U1 | 5 |
| 2019-01-05 00:00:00 | A5 | U1 | 15 |
| 2019-01-05 00:00:00 | A6 | U3 | 16 |
| 2019-01-05 00:00:00 | A7 | U3 | 18 |
| 2019-01-05 00:00:00 | A8 | U1 | 21 |
| 2019-01-06 00:00:00 | A2 | U2 | 22 |
| 2019-01-06 00:00:00 | A3 | U1 | 2 |
| 2019-01-06 00:00:00 | A1 | U1 | 12 |
| 2019-01-06 00:00:00 | A6 | U3 | 9 |
| 2019-01-06 00:00:00 | A5 | U1 | 8 |
| 2019-01-06 00:00:00 | A4 | U1 | 5 |
| 2019-01-07 00:00:00 | A5 | U1 | 24 |
| 2019-01-07 00:00:00 | A4 | U1 | 12 |
| 2019-01-07 00:00:00 | A3 | U1 | 16 |
| 2019-01-07 08:00:00 | A5 | U1 | 28 |
| 2019-01-09 00:00:00 | A8 | U1 | 27 |
DATE_ACCUMULATE
此函数返回一定时间范围内的数据进行累计计算的结果。只能在新增指标或者 API 查询中使用。
函数语法
text
date_accumulate(function1(function2(expression)), date expression1, reset period)参数说明
function1
必填,累计计算的计算类型,可选值为:sum、avg、min、max。
function2
必填,数据的基础运算,必须是基础聚合运算,可选值为:sum、avg、min、max、percentile、count、distinct_count。
expression
必填,要参与计算的字段。
date expression1
必填,基础计算的时间维度。图表中维度必须包含与 date expression1 相同的时间维度,才可以用此指标。summarize 函数的非聚合参数中也必须包含与 date expression1 相同的时间维度,才可以在聚合参数中使用这个函数。
reset period
必填,累计计算的重复周期,计算时会在每个周期的起点清零并重新计算。可选值为:hour、day、week、month、quarter、year。
返回值类型
NUMBER
示例1
用新增指标计算每周的累计 engergy 平均值。
- 用下面的高级表达式新增指标:
text
date_accumulate(sum(avg({energy})), day({logindate}), 'week')- 新建图表,维度选择{logindate},计算方式选择按天,拖入{energy}平均值做为度量,然后拖入上面的指标做为度量。
- 下面是计算结果:
json
{
"data": {
"data": [
[
"2019-01-05",
16.8750000000000000,
16.8750000000000000
],
[
"2019-01-06",
9.6666666666666667,
26.5416666666666667
],
[
"2019-01-07",
20.0000000000000000,
20.0000000000000000
],
[
"2019-01-09",
27.0000000000000000,
47.0000000000000000
]
],
"schema": [
{
"fieldName": "u_6f28278382639341_0"
},
{
"fieldName": "u_7cd2518b65642b48_1"
},
{
"fieldName": "u_c3f773f19fcb0912_2"
}
]
}
}示例2
用 HE 查询计算每周的累计 engergy 平均值。累计计算的时候只算 userType='U1' 的数据。
text
{"kind":"formula","op":"summarize(dataset(1), day({logindate}), avg({energy}), date_accumulate(sum(avg({energy}) filter (where {usertype} = 'U1')), day({logindate}), 'week'))"}下面是计算结果:
json
{
"data": {
"data": [
[
"2019-01-05",
16.875,
16.2
],
[
"2019-01-06",
9.6666666666666667,
22.95
],
[
"2019-01-07",
20,
20
],
[
"2019-01-09",
27,
47
]
],
"schema": [
{
"fieldName": "hs_new_field_1"
},
{
"fieldName": "hs_new_field_2"
},
{
"fieldName": "hs_new_field_3"
}
]
}
}DATE_COMPARE
此函数返回数据相对于指定日期的环比对比值。
函数语法
text
date_compare(function(expression), date expression1, date expression2)参数说明
function
必填,数据的基础运算,必须是基础聚合运算,可选值为:sum、avg、min、max、percentile、count、distinct_count。
date expression1
必填,基础计算的时间维度。图表中维度必须包含与 date expression1 相同的时间维度,才可以用此指标。summarize 函数的非聚合参数中也必须包含与 date expression1 相同的时间维度,才可以在聚合参数中使用这个函数。
date expression2
必填,对比时间维度。
返回值类型
NUMBER
示例1
用新增指标计算两天前 engergy求和的对比值。
- 用下面的高级表达式新增指标:
text
date_compare(sum({energy}), day({logindate}), add_day(day({logindate}), -2))- 新建图表,维度选择{logindate},计算方式选择按天,拖入{energy}求和做为度量,然后拖入上面的指标做为度量。
- 下面是计算结果:
json
{
"data": {
"data": [
[
"2019-01-05",
135,
null
],
[
"2019-01-06",
58,
null
],
[
"2019-01-07",
80,
135
],
[
"2019-01-09",
27,
80
]
],
"schema": [
{
"fieldName": "u_6f28278382639341_0"
},
{
"fieldName": "u_7cd2518b65642b48_2"
},
{
"fieldName": "u_c8f6e35a15596acf_3"
}
]
}
}示例2
用 HE 计算两天前 engergy求和的增长率。
text
{"kind":"formula","op":"summarize(dataset(1), day({logindate}), sum({energy}), growth_rate(sum({energy}), date_compare(sum({energy}), day({logindate}), add_day(day({logindate}), -2))))"}下面是计算结果:
json
{
"data": {
"data": [
[
"2019-01-09",
27,
-0.6625
],
[
"2019-01-06",
58,
null
],
[
"2019-01-07",
80,
-0.40740740740740740741
],
[
"2019-01-05",
135,
null
]
],
"schema": [
{
"fieldName": "hs_new_field_1"
},
{
"fieldName": "hs_new_field_2"
},
{
"fieldName": "hs_new_field_3"
}
]
}
}PREVIOUS
此函数和图表轴里的时间维度配合,返回数据相对于指定日期的环比对比值。
函数语法
text
PREVIOUS(function(expression), period, delta)参数说明
function
必填,数据的基础运算,必须是基础聚合运算,可选值为:sum、avg、min、max、percentile、count、distinct_count。
period
选填,表示要进行比较的粒度,可选值为:year、quarter、month、week、day、hour。没有值的情况下,它会取图表中粒度最小的时间轴。
delta
选填,表示要比较的时间偏移量,类型为整数。
返回值类型
NUMBER
示例1
用新增指标计算 engergy 求和的日环比对比值。
- 用下面的高级表达式新增指标:
text
previous(sum({energy}))- 新建图表,维度选择{logindate},计算方式选择按天,拖入{energy}求和做为度量,然后拖入上面的指标做为度量。
- 下面是计算结果:
json
{
"data": {
"data": [
[
"2019-01-05",
135,
null
],
[
"2019-01-06",
58,
135
],
[
"2019-01-07",
80,
58
],
[
"2019-01-09",
27,
null
]
],
"schema": [
{
"fieldName": "u_6f28278382639341_0"
},
{
"fieldName": "u_7cd2518b65642b48_2"
},
{
"fieldName": "u_c8f6e35a15596acf_3"
}
]
}
}CUSTOM_FILTERS
自定义筛选器计算
函数语法
text
CUSTOM_FILTERS(expression, [{field1},{field2}], condition)参数说明
expression
必填,必须是基础聚合运算。
[{field1},{field2}]
选填,null 表示不删除上文的过滤器,[] 表示删除上文中的所有过滤器,field1/field2 表示过滤器中使用了任意这些字段,那么这个过滤器就会被删除。
condition
选填,计算 expression 时需要新加的过滤条件。
返回值类型
同 expression 的返回类型
示例1
用新增指标计算 engergy 求和,删除上文中的 logindate 相关的过滤器,添加新的时间过滤。
- 用下面的高级表达式新增指标:
text
custom_filters(sum({energy}),[{logindate}],{logindate}='2000-01-01')DATE_SHIFT
移动计算,此函数根据时间序列,逐项推移,依次对一定项数进行统计。
函数语法
text
date_shift(function1(function2(expression)), date expression, lowExpr, upperExpr)参数说明
function1
必填,移动计算的计算类型,可选值为:sum、avg、min、max。
function2
必填,数据的基础运算,必须是基础聚合运算,可选值为:sum、avg、min、max、percentile、count、distinct_count。
expression
必填,要参与计算的字段。
date expression1
必填,基础计算的时间维度。图表中维度必须包含与 date expression1 相同的时间维度,才可以用此指标。summarize 函数的非聚合参数中也必须包含与 date expression1 相同的时间维度,才可以在聚合参数中使用这个函数。
lowExpr
必填,移动计算往前偏移的量,类型是number。
upperExpr
必填,移动计算往后偏移的量,类型是number。
返回值类型
NUMBER
示例1
往前偏移一天,往后偏移一天,移动计算engergy求和的累加值。用新增指标计算。
- 用下面的高级表达式新增指标:
text
date_shift(sum(sum({energy})), day({logindate}), -1, 1)- 新建图表,维度选择{logindate},计算方式选择按天,拖入{energy}求和做为度量,然后拖入上面的指标做为度量。
- 下面是计算结果:
json
{
"data": {
"data": [
[
"2019-01-05",
135,
193
],
[
"2019-01-06",
58,
273
],
[
"2019-01-07",
80,
138
],
[
"2019-01-09",
27,
27
]
],
"schema": [
{
"fieldName": "u_6f28278382639341_0"
},
{
"fieldName": "u_7cd2518b65642b48_2"
},
{
"fieldName": "u_2fb8394ac0a23a02_3"
}
]
}
}示例2
往前偏移一天,往后偏移一天,移动计算engergy求和的累加值。用 HE 计算。
text
{"kind":"formula","op":"summarize(dataset(1), day({logindate}), sum({energy}), date_shift(sum(sum({energy})), day({logindate}), -1, 1))"}```下面是计算结果:
json
{
"data": {
"data": [
[
"2019-01-09",
27,
27
],
[
"2019-01-06",
58,
273
],
[
"2019-01-07",
80,
138
],
[
"2019-01-05",
135,
193
]
],
"schema": [
{
"fieldName": "hs_new_field_1"
},
{
"fieldName": "hs_new_field_2"
},
{
"fieldName": "hs_new_field_3"
}
]
}
}repetition_count
重复计算,此函数计算数据的重复次数。
函数语法
text
repetition_count(expression)参数说明
expression
必填,要参与计算的字段。
返回值类型
NUMBER
示例1
用计算指标计算每种类型的 username 的重复出现次数。
- 用下面的高级表达式新增指标:
text
repetition_count({username})- 新建图表,维度选择{logindate},计算方式选择按天,然后拖入上面的指标做为度量。
- 下面是计算结果:
json
{
"data": {
"data": [
[
"2019-01-05",
0
],
[
"2019-01-06",
0
],
[
"2019-01-07",
2
],
[
"2019-01-09",
0
]
],
"schema": [
{
"fieldName": "u_6f28278382639341_0"
},
{
"fieldName": "u_409214f201c6ce01_2"
}
]
}
}示例2
用 HE 计算每种类型的 username 的重复出现次数。
text
{"kind":"formula","op":"summarize(dataset(1), {usertype}, repetition_count({username}))"}下面是计算结果:
json
{
"data": {
"data": [
[
"U2",
2
],
[
"U1",
14
],
[
"U3",
2
]
],
"schema": [
{
"fieldName": "usertype"
},
{
"fieldName": "hs_new_field_1"
}
]
}
}repetition
重复计算,按照条件,返回数据的重复数。
函数语法
text
repetition(expression, lowExpr, upperExpr)参数说明
expression
必填,要参与计算的字段。
lowExpr
必填,最少重复次数,类型是 number。
upperExpr
必填,最大重复次数,类型是 number。
返回值类型
NUMBER
示例1
用计算指标计算每种类型下 username 出现次数在两次到三次之前的重复数。
- 用下面的高级表达式新增指标:
text
repetition({username}, 2, 3)- 新建图表,维度选择{userType},然后拖入上面的指标做为度量。
- 下面是计算结果:
json
{
"data": {
"data": [
[
"U1",
4
],
[
"U2",
1
],
[
"U3",
1
]
],
"schema": [
{
"fieldName": "u_452a834347a47a1e_0"
},
{
"fieldName": "u_34393f485a5d2eb3_1"
}
]
}
}示例2
用 HE 计算每种类型下 username 出现次数在两次到三次之前的重复数。
text
{"kind":"formula","op":"summarize(dataset(1), {usertype}, repetition({username}, 2, 3))"}下面是计算结果:
json
{
"data": {
"data": [
[
"U2",
1
],
[
"U1",
4
],
[
"U3",
1
]
],
"schema": [
{
"fieldName": "usertype"
},
{
"fieldName": "hs_new_field_1"
}
]
}
}retention
时间维度下的留存/活跃计算,该函数返回数据在指定时间内的留存数或者活跃数。
函数语法
text
retention(expression, date expression, lowExpr, upperExpr, includeStartExpr, includeEndExpr, excludeStartExpr, excludeEndExpr)参数说明
expression
必填,要参与计算的字段。
date expression
必填,留存的时间维度。图表中维度必须包含与 date expression 相同的时间维度,才可以用此指标。summarize 函数的非聚合参数中也必须包含与 date expression 相同的时间维度,才可以在聚合参数中使用这个函数。
lowExpr
必填,留存/活跃时间的开始。
upperExpr
必填,留存/活跃时间的结束,要比实际的结束时间多一天。
includeStartExpr
非必填,计算的字段需要存在的时间段开始时间。
includeEndExpr
非必填,计算的字段需要存在的时间段结束时间。
excludeStartExpr
非必填,计算的字段不能存在的时间段开始时间。
excludeEndExpr
非必填,计算的字段不能存在的时间段结束时间。
includeStartExpr,includeEndExpr,excludeStartExpr,excludeEndExpr必须一起存在,或者一起消失,而且顺序要求严格。
返回值类型
NUMBER
示例1
用计算指标计算username 在接下来的第一天和第二天的留存数。
- 用下面的高级表达式新增指标:
text
retention({username}, day({logindate}), dayadd(day({logindate}), 1), dayadd(day({logindate}), 3))- 新建图表,维度选择{logindate},然后拖入上面的指标做为度量。
- 下面是计算结果:
json
{
"data": {
"data": [
[
"2019-01-05",
6
],
[
"2019-01-06",
3
],
[
"2019-01-07",
0
],
[
"2019-01-09",
0
]
],
"schema": [
{
"fieldName": "u_6f28278382639341_0"
},
{
"fieldName": "u_cbc569ab32ff31d1_2"
}
]
}
}示例2
用 HE 计算username 在前一天前二天的活跃数。
json
{
"kind": "formula",
"op": "summarize(dataset(1), day({logindate}), retention({username}, day({logindate}), dayadd(day({logindate}), -2), dayadd(day({logindate}), 0)))"
}下面是计算结果:
json
{
"data": {
"data": [
[
"2019-01-09",
0
],
[
"2019-01-06",
6
],
[
"2019-01-07",
3
],
[
"2019-01-05",
0
]
],
"schema": [
{
"fieldName": "hs_new_field_1"
},
{
"fieldName": "hs_new_field_2"
}
]
}
}示例3
用计算指标计算新username 在接下来的第一天和第二天的留存数。
- 用下面的高级表达式新增指标:
text
retention({username}, day({logindate}), dayadd(day({logindate}), 1), dayadd(day({logindate}), 3), null, null, null, day({logindate}))- 新建图表,维度选择{logindate},然后拖入上面的指标做为度量。
- 下面是计算结果:
json
{
"data": {
"data": [
[
"2019-01-05",
6
],
[
"2019-01-06",
null
],
[
"2019-01-07",
null
],
[
"2019-01-09",
null
]
],
"schema": [
{
"fieldName": "u_6f28278382639341_0"
},
{
"fieldName": "u_cbc569ab32ff31d1_2"
}
]
}
}continuous_retention
时间维度下的连续活跃计算,该函数返回数据在指定时间内的连续活跃数。
函数语法
text
continuous_retention(expression, date expression, lowExpr, upperExpr, period)参数说明
expression
必填,要参与计算的字段。
date expression
必填,留存的时间维度。图表中维度必须包含与 date expression 相同的时间维度,才可以用此指标。summarize 函数的非聚合参数中也必须包含与 date expression 相同的时间维度,才可以在聚合参数中使用这个函数。
lowExpr
必填,留存/活跃时间的开始。
upperExpr
必填,留存/活跃时间的结束,要比实际的结束时间多一天。
period
必填,活跃周期,类型是String,可选值是:day、week、month、quarter、year。
返回值类型
NUMBER
示例1
用计算指标计算username 在昨天和前天的连续活跃数。
- 用下面的高级表达式新增指标:
text
continuous_retention({username}, day({logindate}), dayadd(day({logindate}), -2), dayadd(day({logindate}), 0), 'day')- 新建图表,维度选择{logindate},然后拖入上面的指标做为度量。
- 下面是计算结果:
json
{
"data": {
"data": [
[
"2019-01-05",
0
],
[
"2019-01-06",
0
],
[
"2019-01-07",
3
],
[
"2019-01-09",
0
]
],
"schema": [
{
"fieldName": "u_6f28278382639341_0"
},
{
"fieldName": "u_34393f485a5d2eb3_1"
}
]
}
}示例2
用 HE 计算username 在昨天和前天的连续活跃率。
json
{
"kind": "formula",
"op": "summarize(dataset(1), day({logindate}), growth_rate(distinct_count({username}), continuous_retention({username}, day({logindate}), dayadd(day({logindate}), -2), dayadd(day({logindate}), 0), 'day')))"
}下面是计算结果:
json
{
"data": {
"data": [
[
"2019-01-05",
null
],
[
"2019-01-06",
null
],
[
"2019-01-07",
0
],
[
"2019-01-09",
null
]
],
"schema": [
{
"fieldName": "hs_new_field_1"
},
{
"fieldName": "hs_new_field_2"
}
]
}
}static_retention
非时间维度的留存/活跃计算,该函数返回数据在指定时间段间的留存数。
函数语法
text
static_retention(expression, date expression, start date, end date, compare start date, compare end date, includeStartExpr, includeEndExpr, excludeStartExpr, excludeEndExpr)参数说明
expression
必填,要参与计算的字段。
date expression
必填,计算活跃的时间字段。
start date
必填,要计算的开始时间,类型是时间。
end date
必填,要计算的结束时间,类型是时间。比实际的结束时间要晚一天。
compare start date
必填,要计算的留存周期的开始时间,类型是时间。
compare end date
必填,要计算的留存周期的结束时间,类型是时间。比实际的留存周期结束时间要晚一天。
includeStartExpr
非必填,计算的字段需要存在的时间段开始时间。
includeEndExpr
非必填,计算的字段需要存在的时间段结束时间。
excludeStartExpr
非必填,计算的字段不能存在的时间段开始时间。
excludeEndExpr
非必填,计算的字段不能存在的时间段结束时间。
includeStartExpr,includeEndExpr,excludeStartExpr,excludeEndExpr必须一起存在,或者一起消失,而且顺序要求严格。
返回值类型
NUMBER
示例1
用计算指标计算在 2019-01-05 到 2019-01-06时间段内在线的 username,留存到接下来的1到3天的数量。
- 用下面的高级表达式新增指标:
text
static_retention({username}, {logindate}, '2019-01-05', '2019-01-07', '2019-01-07', '2019-01-10')- 新建图表,维度选择{usertype},然后拖入上面的指标做为度量。
- 下面是计算结果:
json
{
"data": {
"data": [
[
"U1",
4
],
[
"U2",
0
],
[
"U3",
0
]
],
"schema": [
{
"fieldName": "u_452a834347a47a1e_0"
},
{
"fieldName": "u_55c18b8d38923c85_2"
}
]
}
}示例2
用 HE 计算在 2019-01-07 到 2019-01-09时间段内在线的 username,在2019-01-05的活跃数量。
json
{
"kind": "formula",
"op": "summarize(dataset(1), {usertype}, static_retention({username}, {logindate}, '2019-01-07', '2019-01-10', '2019-01-05', '2019-01-06'))"
}下面是计算结果:
json
{
"data": {
"data": [
[
"U2",
0
],
[
"U1",
4
],
[
"U3",
0
]
],
"schema": [
{
"fieldName": "usertype"
},
{
"fieldName": "hs_new_field_1"
}
]
}
}示例3
用计算指标计算在 2019-01-05 到 2019-01-06时间段内在线的老 username,留存到接下来的1到3天的数量。
- 用下面的高级表达式新增指标:
text
static_retention({username}, {logindate}, '2019-01-05', '2019-01-07', '2019-01-07', '2019-01-10', null, '2019-01-05', null, null)- 新建图表,维度选择{usertype},然后拖入上面的指标做为度量。
- 下面是计算结果:
json
{
"data": {
"data": [
[
"U1",
4
],
[
"U2",
0
],
[
"U3",
0
]
],
"schema": [
{
"fieldName": "u_452a834347a47a1e_0"
},
{
"fieldName": "u_55c18b8d38923c85_2"
}
]
}
}static_retention_rate
非时间维度的留存/活跃计算,该函数返回数据在指定时间段间的留存率。
函数语法
text
static_retention_rate(expression, date expression, start date, end date, compare start date, compare end date)参数说明
expression
必填,要参与计算的字段。
date expression
必填,计算活跃的时间字段。
start date
必填,要计算的开始时间,类型是时间。
end date
必填,要计算的结束时间,类型是时间。比实际的结束时间要晚一天。
compare start date
必填,要计算的留存周期的开始时间,类型是时间。
compare end date
必填,要计算的留存周期的结束时间,类型是时间。比实际的留存周期结束时间要晚一天。
返回值类型
NUMBER
示例1
用计算指标计算在 2019-01-05 到 2019-01-06时间段内在线的 username,在接下来的1到3天的留存率。
- 用下面的高级表达式新增指标:
text
static_retention_rate({username}, {logindate}, '2019-01-05', '2019-01-07', '2019-01-07', '2019-01-10')- 新建图表,维度选择{usertype},然后拖入上面的指标做为度量。
- 下面是计算结果:
json
{
"data": {
"data": [
[
"U1",
0.80000000000000000000
],
[
"U2",
0E-20
],
[
"U3",
0E-20
]
],
"schema": [
{
"fieldName": "u_452a834347a47a1e_0"
},
{
"fieldName": "u_6ef7c5c463a74495_1"
}
]
}
}示例2
用 HE 计算在 2019-01-07 到 2019-01-09时间段内在线的 username,在2019-01-05的活跃率。
json
{
"kind": "formula",
"op": "summarize(dataset(1), {usertype}, static_retention_rate({username}, {logindate}, '2019-01-07', '2019-01-10', '2019-01-05', '2019-01-06'))"
}下面是计算结果:
json
{
"data": {
"data": [
[
"U2",
null
],
[
"U1",
1
],
[
"U3",
null
]
],
"schema": [
{
"fieldName": "usertype"
},
{
"fieldName": "hs_new_field_1"
}
]
}
}static_continuous_retention
非时间维度的连续活跃计算,该函数返回数据在指定时间段间的连续活跃数。
函数语法
text
static_continuous_retention(expression, date expression, start date, end date, compare start date, compare end date, period)参数说明
expression
必填,要参与计算的字段。
date expression
必填,计算活跃的时间字段。
start date
必填,要计算的开始时间,类型是时间。
end date
必填,要计算的结束时间,类型是时间。比实际的结束时间要晚一天。
compare start date
必填,要计算的留存周期的开始时间,类型是时间。
compare end date
必填,要计算的留存周期的结束时间,类型是时间。比实际的留存周期结束时间要晚一天。
period
必填,活跃周期,类型是String,可选值是:day、week、month、quarter、year。
返回值类型
NUMBER
示例1
用计算指标计算今天在线的 username,在前一年到两年里的连续活跃数,活跃周期为年。
- 用下面的高级表达式新增指标:
text
static_continuous_retention({username}, {logindate}, day(now()), dayadd(day(now()), 1), yearadd(year(now()), -2), yearadd(year(now()), 0), 'year')- 新建图表,维度选择{usertype},然后拖入上面的指标做为度量。
- 下面是计算结果:
json
{
"data": {
"data": [
[
"U1",
0
],
[
"U2",
0
],
[
"U3",
0
]
],
"schema": [
{
"fieldName": "u_452a834347a47a1e_0"
},
{
"fieldName": "u_c126c85c957b406e_2"
}
]
}
}static_continuous_retention_rate
非时间维度的连续活跃计算,该函数返回数据在指定时间段间的连续活跃率。
函数语法
text
static_continuous_retention_rate(expression, date expression, start date, end date, compare start date, compare end date, period)参数说明
expression
必填,要参与计算的字段。
date expression
必填,计算活跃的时间字段。
start date
必填,要计算的开始时间,类型是时间。
end date
必填,要计算的结束时间,类型是时间。比实际的结束时间要晚一天。
compare start date
必填,要计算的留存周期的开始时间,类型是时间。
compare end date
必填,要计算的留存周期的结束时间,类型是时间。比实际的留存周期结束时间要晚一天。
period
必填,活跃周期,类型是String,可选值是:day、week、month、quarter、year。
返回值类型
NUMBER
示例1
用 HE 计算今天在线的 username,在前一年到两年里的连续活跃数,活跃周期为年。
text
{"kind":"formula","op":"summarize(dataset(1), {usertype}, static_continuous_retention({username}, {logindate}, day(now()), dayadd(day(now()), 1), yearadd(year(now()), -2), yearadd(year(now()), 0), 'year'))"}下面是计算结果:
json
{
"data": {
"data": [
[
"U2",
0
],
[
"U1",
0
],
[
"U3",
0
]
],
"schema": [
{
"fieldName": "usertype"
},
{
"fieldName": "hs_new_field_1"
}
]
}
}高级行计算函数
高级行计算函数是衡石内部需要改写它为复杂逻辑才能运行的函数。
top_n
保留某列在指定分组和排序下的前n个值,其余值统一为特殊值
函数语法
text
top_n(N, field1, constant1) over([ PARTITION BY expr1 ] ORDER BY expr2 [ DESC ])参数说明
N
必填,需要保留的值的个数。
field1
必填,要保留值的字段名。
constant1
必填,非保留值要统一表示为的值,它需要和 field1 的字段类型相同。
expr1
选填,分组字段,如果有分组字段,就表示在该分组下去计算 field1 的保留值。
expr2
必填,对 field1 的排序规则,通常它是 field1 本身或者是其它字段的聚合值。
返回值类型
同 field1 的字段类型
示例1
以 userType 为分组,保留按照 count({energy}) 排名前2的username,其余的用 "其它" 表示。
text
{"kind":"formula","op":"summarize(dataset(2),{usertype} as t1, top_n(2, {username}, '其它') over(PARTITION BY {usertype} order by count({energy}) asc) as test)"}bottom_n
保留某列在指定分组和排序下的前n个值,其余值统一为特殊值
函数语法
text
bottom_n(N, field1, constant1) over([ PARTITION BY expr1 ] ORDER BY expr2 [ DESC ])参数说明
N
必填,需要保留的值的个数。
field1
必填,要保留值的字段名。
constant1
必填,非保留值要统一表示为的值,它需要和 field1 的字段类型相同。
expr1
选填,分组字段,如果有分组字段,就表示在该分组下去计算 field1 的保留值。
expr2
必填,对 field1 的排序规则,通常它是 field1 本身或者是其它字段的聚合值。
返回值类型
同 field1 的字段类型
示例1
以 userType 为分组,保留按照 count({energy}) 排名最后2名的username,其余的用 "其它" 表示。
text
{"kind":"formula","op":"summarize(dataset(2),{usertype} as t1, bottom_n(2, {username}, '其它') over(PARTITION BY {usertype} order by count({energy}) asc) as test)"}CALCULATE
预先计算出来一些数据,然后和原始的数据一起计算图表的数据,一般用于新建指标或者图表过滤中。用于指标计算的时候,它的外层需要有合适的聚合计算函数。图表中的 calculate 表达式的值会随着小计发生变化,明细数据计算的维度和小计的维度不同从而影响calculate表达式的值。
函数语法
text
CALCULATE(ARG1, [ARG2],... )参数说明
ARG1
预先计算数据所需的表达式
ARG2
非必填,可以是多个,表示要删除的图表中的分组字段
返回值类型
任意类型
示例1
比如图表中维度有 prime_genre 和 month,度量是 votes 求和。过滤条件是按照 prime_genre 分组的 votes 求和中排名前三的。过滤条件的写法如下。
text
calculate(rank() OVER (ORDER BY sum({votes}) ASC), {prime_genre}) < 4CALCULATEP
预先计算出来一些数据,然后和原始的数据一起计算图表的数据,一般用于新建指标或者图表过滤中。用于指标计算的时候,它的外层需要有合适的聚合计算函数。图表中的 calculatep 表达式的值不会被小计影响。
函数语法
text
CALCULATEP(ARG1, [ARG2],... )参数说明
ARG1
预先计算数据所需的表达式
ARG2
非必填,可以是多个,表示要删除的图表中的分组字段
返回值类型
任意类型
示例1
比如图表中维度有 prime_genre 和 month,度量是 votes 求和。过滤条件是按照 prime_genre 分组的 votes 求和中排名前三的。过滤条件的写法如下。
text
calculate(rank() OVER (ORDER BY sum({votes}) ASC), {prime_genre}) < 4CALCULATEX
预先计算出来一些数据,然后和原始的数据一起计算图表的数据,一般用于新建指标或者图表过滤中。用于指标计算的时候,它的外层需要有合适的聚合计算函数。它不受维度控制,所以也可以用在维度上。
函数语法
text
CALCULATEX(ARG1, ARG2,... )参数说明
ARG1
预先计算数据所需的表达式
ARG2
必填,计算表达式所需的分组。
返回值类型
任意类型
示例1
比如图表度量是 votes 求和。过滤条件是按照 prime_genre 分组的 votes 求和中排名前三的。过滤条件的写法如下。
text
calculatex(rank() OVER (ORDER BY sum({votes}) ASC), {prime_genre}) < 4数据集函数
此类函数的返回结果都是数据集数据 datasetResultDto。 此类函数说明的示例都是基于数据库中的 movie 表,它的访问路径是 test。 下面是 movie 的数据。在衡石系统中新建的数据连接 id 为 1, 新建的应用 id 为1,新建的数据集 id 为1。
| id | type | name | votes |
|---|---|---|---|
| 1 | 动画 | 狮子王 | 8.5 |
| 2 | 喜剧 | 疯狂的外星人 | 8.2 |
| 3 | 动画 | 冰雪奇缘 | 8.1 |
| 4 | 喜剧 | 唐人街探案 | 8.3 |
DB_SOURCE
此函数返回connection下的某个表内容
函数语法
text
db_source({connectionId}, {path}, {tableName})参数说明
connectionId
必填,当前系统里配置的数据连接 id。可选类型:NUMBER
path
必填,表的访问路径,要用数据库默认,可以填[]. 可选类型:STRING 数组
tableName
必填,要查询的表名。可选类型:STRING
返回值类型
示例
text
db_source(1,['test'], 'movie')下面是返回结果:
json
{
"data": {
"data": [
[
1,
"动画",
"狮子王",
8.5
],
[
2,
"喜剧",
"疯狂的外星人",
8.2
],
[
3,
"动画",
"冰雪奇缘",
8.1
],
[
4,
"喜剧",
"唐人街探案",
8.3
]
],
"schema": [
{
"fieldName": "id",
"visible": true,
"nativeType": "int4"
},
{
"fieldName": "type",
"visible": true,
"nativeType": "text"
},
{
"fieldName": "name",
"visible": true,
"nativeType": "text"
},
{
"fieldName": "votes",
"visible": true,
"nativeType": "numeric"
}
]
}
}DATASET
此函数返回某个数据集的数据, 这个函数必须在有应用的语境下才可以用。
函数语法
text
dataset({id})参数说明
id
必填,数据集的 id 。可选类型:NUMBER
返回值类型
示例
text
dataset(1)返回结果见DB_SOURCE的示例返回结果
APP_DATASET
此函数返回某个应用下的某个数据集的数据。
函数语法
text
app_dataset({appId}, {datasetId})参数说明
appId
必填,应用的 id 。可选类型:NUMBER
datasetId
必填,数据集的 id 。可选类型:NUMBER
返回值类型
示例
text
app_dataset(1, 1)返回结果见DB_SOURCE的示例返回结果
FILTER
此函数返回过滤后的数据集数据。
函数语法
text
filter({dataset expression}, {filter expression})参数说明
dataset expression
必填,返回结果是 dataset 的表达式, 可选范围是数据集函数下的函数表达式。可选类型: DATASET
datasetId
必填,返回结果是 bool 的表达式。 可选类型: BOOL
返回值类型
示例
text
filter(app_dataset(1, 1), {votes} > 8.2)json
{
"data": {
"data": [
[
1,
"动画",
"狮子王",
8.5
],
[
4,
"喜剧",
"唐人街探案",
8.3
]
],
"schema": [
{
"fieldName": "id",
"visible": true,
"nativeType": "int4"
},
{
"fieldName": "type",
"visible": true,
"nativeType": "text"
},
{
"fieldName": "name",
"visible": true,
"nativeType": "text"
},
{
"fieldName": "votes",
"visible": true,
"nativeType": "numeric"
}
]
}
}SELECT_FIELDS
此函数返回数据集中选定的列的数据。每个列的运算都是独立的,不会相互影响。
函数语法
text
select_fields({dataset expression}, {field1}, {field2} ...)参数说明
dataset expression
必填,返回结果是 dataset 的表达式, 可选范围是数据集函数下的函数表达式。可选类型: DATASET
field1, field2 ...
必填,参数数量可变,最少为1,描述列的表达式。 参数不可以用数据集中的新增指标。
返回值类型
示例1
text
select_fields(filter(app_dataset(1, 1), {votes} < 8.3), {id}, {type} as {类型}, {votes} - 8 as {分数尾数})下面是返回结果:
json
{
"data": {
"data": [
[
1,
"动画",
0.5
],
[
4,
"喜剧",
0.3
]
],
"schema": [
{
"fieldName": "id",
"visible": true,
"nativeType": "int4"
},
{
"fieldName": "类型",
"visible": true,
"nativeType": "text"
},
{
"fieldName": "分数尾数",
"visible": true,
"nativeType": "numeric"
}
]
}
}示例2
text
select_fields(app_dataset(1, 1), {type}, sum({votes}) as {总票数})下面是返回结果:
json
{
"data": {
"data": [
[
"动画",
33.1
],
[
"喜剧",
33.1
],
[
"动画",
33.1
],
[
"喜剧",
33.1
]
],
"schema": [
{
"fieldName": "type",
"visible": true,
"nativeType": "text"
},
{
"fieldName": "总票数",
"visible": true,
"nativeType": "numeric"
}
]
}
}SUMMARIZE
此函数返回数据集中选定的列的数据。不同列的运算是相互影响的。根据非聚合列分组后,再计算聚合列。
函数语法
text
summarize({dataset expression}, {field1}, {field2} ...)参数说明
dataset expression
必填,返回结果是 dataset 的表达式, 可选范围是数据集函数下的函数表达式。可选类型: DATASET
field1, field2 ...
必填,参数数量可变,最少为1,描述列的表达式。
返回值类型
示例1
text
summarize(app_dataset(1, 1), {type})下面是返回结果:
json
{
"data": {
"data": [
[
"喜剧"
],
[
"动画"
]
],
"schema": [
{
"fieldName": "type",
"visible": true,
"nativeType": "text"
}
]
}
}示例2
text
summarize(app_dataset(1, 1), {type}, sum({votes}) as {sum1}, max({votes}) as {max1})下面是返回结果:
json
{
"data": {
"data": [
[
"喜剧",
16.5,
8.3
],
[
"动画",
16.6,
8.5
]
],
"schema": [
{
"fieldName": "type",
"visible": true,
"nativeType": "text"
},
{
"fieldName": "sum1",
"visible": true,
"nativeType": "numeric"
},
{
"fieldName": "max1",
"visible": true,
"nativeType": "numeric"
}
]
}
}SELECT_FIELDS_COMPLETE
此函数返回数据集中选定的列的数据。每个列的运算都是独立的,不会相互影响。同 SELECT_FIELDS 不同的是,它可以加入过滤条件、排序、分页信息。
函数语法
text
select_fields_complete({dataset expression},
[{field1},{field2},{field3} ...],
[filter_expr_1,filter_expr_2 ...],
[sort_expr_1,sort_expr_2...],
offset, limit)参数说明
dataset expression
必填,返回结果是 dataset 的表达式, 可选范围是数据集函数下的函数表达式。可选类型: DATASET
[{field1},{field2},{field3} ...]
必填,数组长度没有限制,数组为空的时候表示获取所有字段的信息。
[filter_expr_1,filter_expr_2 ...]
必填,过滤表达式,不同表达式之间是 and 的关系,为空表示没有过滤条件。
[sort_expr_1,sort_expr_2...]
必填,排序字段,写表达式的场景下,这里不支持指定顺序,都是按照升级排序。但是写 HE 结构体的时候,是可以指定顺序的。
offset
必填,获取数据的偏移量。
limit
必填,或者数据的限制条数。
返回值类型
示例1: 写表达式
text
select_fields_complete(dataset(2),[{id},{month}],[{id}>1,{id}<50],[{id}],6,3)下面是返回结果:
json
{
"data": {
"data": [
[
8,
9
],
[
9,
10
],
[
10,
10
]
],
"schema": [
{
"fieldName": "id",
"visible": true,
"type": "number"
},
{
"fieldName": "month",
"visible": true,
"type": "number"
}
]
}
}示例2: 写 HE 结构体
json
{
"kind": "function",
"op": "select_fields_complete",
"args": [
{
"kind": "function",
"op": "dataset",
"args": [
{
"kind": "constant",
"op": 2
}
]
},
[
{
"kind": "field",
"op": "id"
},
{
"kind": "field",
"op": "month"
}
],
[
{
"kind": "function",
"op": ">",
"args": [
{
"kind": "field",
"op": "id"
},
{
"kind": "constant",
"op": 1
}
]
},
{
"kind": "function",
"op": "<",
"args": [
{
"kind": "field",
"op": "id"
},
{
"kind": "constant",
"op": 50
}
]
}
],
[
{
"kind": "field",
"op": "id",
"direction": "desc"
}
],
{
"kind": "constant",
"op": 6
},
{
"kind": "constant",
"op": 3
}
]
}下面是返回结果:
json
{
"data": {
"data": [
[
43,
1
],
[
42,
5
],
[
41,
10
]
],
"schema": [
{
"fieldName": "id",
"visible": true,
"type": "number"
},
{
"fieldName": "month",
"visible": true,
"type": "number"
}
]
}
}SUMMARIZE_COMPLETE
此函数返回数据集中选定的列的数据。不同列的运算是相互影响的。根据非聚合列分组后,再计算聚合列。同 SUMMARIZE 不同的是,它可以加入过滤条件、排序、分页信息。
函数语法
text
summarize_complete({dataset expression},
[expr_1,expr_2 ...],
[filter_expr_1,filter_expr_2 ...],
[having_expr_1,having_expr_2 ...],
[sort_expr_1,sort_expr_2...],
offset, limit)参数说明
dataset expression
必填,返回结果是 dataset 的表达式, 可选范围是数据集函数下的函数表达式。可选类型: DATASET
[expr_1,expr_2 ...]
必填,数组长度没有限制,数组为空的时候表示获取所有字段的信息。表达式中所有非聚合字段都会参与到分组计算中。
[filter_expr_1,filter_expr_2 ...]
必填,过滤表达式,不同表达式之间是 and 的关系,为空表示没有过滤条件。
[having_expr_1,having_expr_2 ...]
必填,过滤表达式,不同表达式之间是 and 的关系,为空表示没有过滤条件。这里是聚合表达式的过滤,对应 sql 中的 having。
[sort_expr_1,sort_expr_2...]
必填,排序字段,写表达式的场景下,这里不支持指定顺序,都是按照升级排序。但是写 HE 结构体的时候,是可以指定顺序的。
offset
必填,获取数据的偏移量。
limit
必填,或者数据的限制条数。
返回值类型
示例1: 写表达式
text
summarize_complete(dataset(2),[{month},count({id})],[{id}>1,{id}<50],[avg({day})>1],[{month}],6,3)下面是返回结果:
json
{
"data": {
"data": [
[
8,
2
],
[
9,
2
],
[
10,
4
]
],
"schema": [
{
"fieldName": "month",
"visible": true,
"type": "number"
},
{
"fieldName": "_hs_uid_0",
"visible": true,
"type": "number"
}
]
}
}示例2: 写 HE 结构体
json
{
"kind": "function",
"op": "summarize_complete",
"args": [
{
"kind": "function",
"op": "dataset",
"args": [
{
"kind": "constant",
"op": 2
}
]
},
[
{
"kind": "field",
"op": "month",
"uid": "month-t1"
},
{
"kind": "function",
"op": "count",
"args": [
{
"kind": "field",
"op": "id"
}
]
}
],
[
{
"kind": "function",
"op": ">",
"args": [
{
"kind": "field",
"op": "id"
},
{
"kind": "constant",
"op": 1
}
]
},
{
"kind": "function",
"op": "<",
"args": [
{
"kind": "field",
"op": "id"
},
{
"kind": "constant",
"op": 50
}
]
}
],
[
{
"kind": "function",
"op": "!=",
"args": [
{
"kind": "reference",
"op": "month-t1"
},
{
"kind": "constant",
"op": 6
}
]
}
],
[
{
"kind": "field",
"op": "month",
"direction": "desc"
}
],
{
"kind": "constant",
"op": 6
},
{
"kind": "constant",
"op": 3
}
]
}下面是返回结果:
json
{
"data": {
"data": [
[
5,
3
],
[
4,
5
],
[
3,
5
]
],
"schema": [
{
"fieldName": "month-t1",
"visible": true,
"type": "number"
},
{
"fieldName": "_hs_uid_0",
"visible": true,
"type": "number"
}
]
}
}